
This is the last part of a series on RESTful services in which I am trying to sum up the things you should know before designing your service layer. While the first section did go over the inspirations and ideas behind the approach, the second one covered core values and properties that services that follow the style should exhibit. In this concluding piece, I will try to list the features a RESTful API should have to be mature, scalable and dependable. I highly suggest reading the first two parts even if you’re a seasoned developer, as you might find some valuable nuggets.
Let’s not waste time.
1. Makes use of Content Types
This is one of the tenets of the web that is widely ignored when it comes REST despite having a significant importance. With content types, web replaces the one, big, custom and ever-changing contract with the little, reusable and stable pieces of contracts for its resources. A componentization of contracts, if you will.
While we mostly see “application/json” as THE content type accepted and returned by the RESTful services on how to interpret its representations, there are more questions to be answered regarding interpretation. Most of them are related to the conventions you are going to put together while you implement the features in these articles. For a consumer to process your representations in a standard way, they need to be able to rely on the rules you play by. First, find out what those rules are. Then, if you can, name your rule-book and disclose it. These rules could evolve in time but don’t fret; they too could be versioned. Better yet, choose one of the existing successful standards like HAL, json api, siren.
2. Have Defined and Distinct Request and Response Models

One aspect of having a defined content-type is having different input and output models, aside from your base resource representation that you use internally in your services. You could think of the decisions you have to make about this in two groups; resource specific and resource independent.
Resource specific decisions involve selecting which of the properties you are going to share with your consumers in your responses that are available in your internal model, and which are the ones that you will accept in the requests. The latter should be decidedly fewer as most of the fields should be immutable in a PUT request, and could only be manipulated with named actions internally that takes specific parameters.
Resource independent ones are, how to represent relations, ids, id collections, links, link collections, etc in your representations. Answers to these questions may and probably should differ in request and response representations. You would want display as much as information as possible in your responses to increase discoverability, while in requests you may want to be more concise to decrease usage faults and bad requests. Again, you may check out standard content type specifications see your options in both cases.
3. Use Moore Machines in your Design
Like the domain driven suggestion in the previous part, this is related to how you approach your problems rather than adding another feature to your back-end. The first point I made in the introduction was, all resources are basically machines. If we want to be more specific we could say; abstract machines that have finite states that they can be in. This kinda sounds like finite-state machines. When you approach the problem that way, having just a class diagram will not be enough when designing the behaviour of your API. But thankfully there is a concept way older UML (1994) to help you with that.
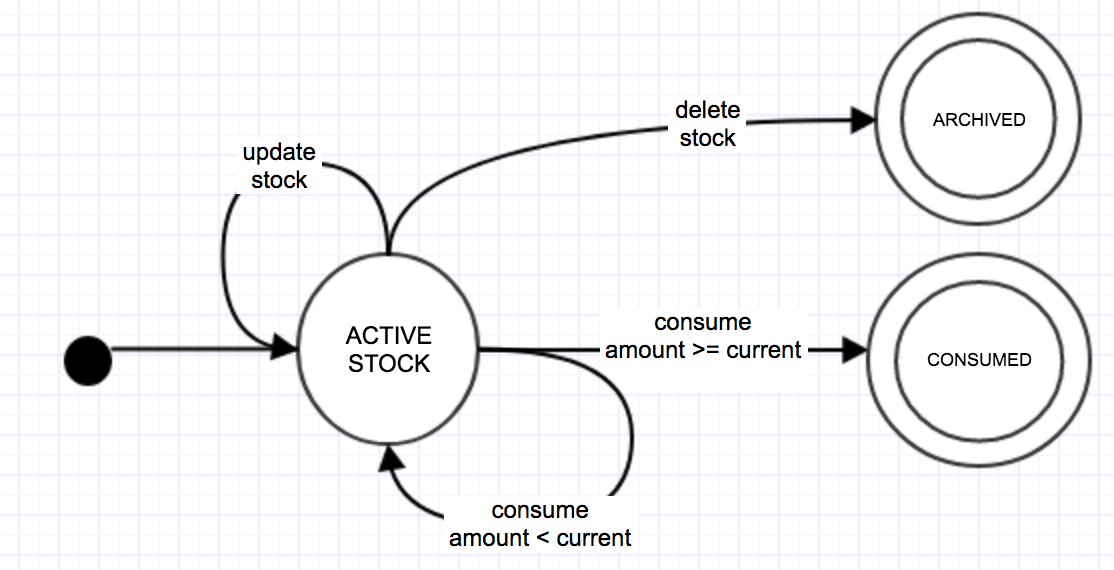
Next in our very smart guys list is someone named Edward F. Moore who presented “Moore Machines” in a paper in 1956. They simulate machines which its output values are determined both by its current state and by the values of the input it receives. This is precisely what we need.
All of your resources should have a life-cycle like this. An adventure that starts with creation (probably with a POST request) that goes through various stages through named transitions with related input, and then finally ends in one of its final states. These final states could be archival caused by a DELETE request, or something more domain specific like expiration or cancellation.

Don’t Delete.
I’m not saying don’t hard-delete here, just don’t delete at all. Nothing ever gets really deleted in real life, so why should they be able to in your API. Archival is part of reality just like death. It may denote the end of an element’s adventure, but they will have their place in history and still may keep their relations to other things. Let’s say we erased a product from an e-commerce system, what would be the status of the orders which has that product then? Do they become inconsistent, or are they to be erased as well? If you retire a resource rather than deleting it, things will start to feel more intuitive. Retirement meaning being closed off for further updates (it’s a final state after all), not being allowed to form new relations, and having most of its current relationships revoked.
4. Use HATEOAS
HATEOAS is one of the cool acronyms that is expanded into something even cooler: Hypermedia as the engine of the application state. It can be simply defined as making use of hypermedia to expose possible transitions of a resource that their consumers can take, letting them propel the state of it forward.
Most of the time, when you send a request to read from a regular ‘Status’ resource that is on a social network back-end, what you get in the response is only its current state; its text, creation time, owner, etc. But when you see the same status update on a webpage that state is accompanied with many things; like buttons by the side of it that lets users like it, delete it, edit it, make it private etc. Users are not expected to find the services that do those things; they are presented with it. They can comfortably manipulate the lifecycle of that status through this presentation. The question is, is there any good reason to rob consumers of your service layer from such convenience? You can easily add these possible transitions to a representation, in addition to resource’s current state. Thus creating a more self-sufficient API that can easily be used by a graphical HTTP client interface like postman, or restlet.
If you are designing your resources in the way suggested in the previous point (with finite state machines) implementing this will become significantly easier. Just try to keep effects of these actions limited to that resource itself. If there are side effects to be had, try to define and invoke those effects through their own actions in their respective resources to keep everything tidy. Lastly, don’t forget to add accepted content type and HTTP method of the invocation of these transitions in your representations since they may vary.
5. Have Good Collections

At least half of your responses will be collections of representations rather than individual instances. Unfortunately, between the two doing former the right way is much more complicated because your users are going to need the ability to manipulate the way they access these collections to fulfil their specific needs. Not unlike their need for a concept like SQL to extract data from RDBMSs. But if a URI should respond with the same logical representation no matter what, how can we provide a way to differentiate the way people access data? The answer lies in the query parameters.
Query parameters, as you might know, are part of the URL after ‘?’ sign. These parameters do not define or identify the resource you are seeing, they qualify and specify its representation. If you ever be in a position where you need to send data to server side via URI tunnelling and have to choose between path params (which are part of URI) and query params, make use of this distinction.
So, what are the features you need to provide through these parameters until your collections are good enough? Here’s a shortlist;
- Filtering: You should provide a way to filter for the entities which your consumers want to see. This is a very complicated problem and to solve it resoundingly you’re probably going to need a powerful DSL. You can look for inspirations from established solutions but try to support at the very least logical operators, comparison operators and text likeness. I like having a JSON based expression that specifies the search and placing its encoded form on a query parameter. This is mainly sacrificing readability for flexibility, so might want to try something different depending on your values.
- Ordering: This one is relatively easy, there is no reason you shouldn’t have simple sorting in your collections. The problem starts to get complicated when you want to have multi-level ordering though. Again, you may need to come up with a simple DSL to support this, but I’d say it is worth it.
- Paging: Another easy one. Make it possible so that your consumer could specify a page number, page size and an offset to access the range they need. Surprisingly the offset, the number that you are going to start paging from, is way more important than the other two as its more flexible. Also, another option for paging chronologically ordered collections is filtering with creation date, as it solves the problem of new entries messing up the order.

6. Resource Expansion
Resource expansion means the ability to include related resources in representations, so that you can access the necessary depth of data in a single request. While this is something relatively harder to implement it’s more than worth it for its benefits. It solves the “n+1” requests problem for representations related to collections and saves you from spending lots of bandwidth and time. All the while providing an excellent developer experience. A proper implementation should work in a cascading manner, so that you should be able to expand the related resources of the already expanded ones, and so on.
We should give an example of how this might work before moving on. Let’s say this is a user representation:
GET '/user/1'
{
...,
name: 'awesome_user',
orders: { uri: '/user/1/orders' }
}In a case where what our users might want to display this users order summaries along with its properties, we should give them to ability to do something along the lines of this:
GET '/user/1?expand=orders(item,seller)'
{
...,
name: 'awesome_user',
orders: {
uri: '/user/1/orders',
content: {
...,
[
{
quantity: 2,
item: {
uri: 'item/5',
content: {
name: 'awesome_item',
...
}
},
seller: {
uri: 'seller/6',
content: { ... }
}
},
{...},
...
]
}
}
}By the way, you might be aware that this feature is more or less the big idea about GraphQL.
7. Use ETag Caching
Making use of ETags as a caching mechanism is so easy and beneficial when you follow the basics of REST, ignoring it would be a waste. Simply, it means sending hashes of the representations in a response header while keeping a map of them keyed with their URIs in the server-side, so that clients could send them back in subsequent requests to check for changes. This saves in both valuable server time in the data access bottleneck, and in client time while reducing bandwidth.
This mechanism is part of the HTTP specification so that you don’t have to do anything specific on the client side. All HTTP clients including browsers support this behaviour natively. How it works on the server side is, when you get a GET with an ETag header you check with the hash map first before you process the request, and when you get any other type of request like POST, PUT, DELETE; you just update the map right before sending the response.
This all works on the basis of URIs identifying the things they return. So things may fall apart if you are responding differently to different people based on their headers even though they’re using the same URI. Try not to do that but if you have to, use URI + ‘Differentiating Token’ as the key of cache map for that resource.
8. Consider API Versioning

As a feature, this is not related to REST. But since there are unique ways to handle this with REST, I figured I should mention it. What you need is to determine how to communicate to the server that what is the expected version of the request. Obviously, when it’s not specified, you can use the latest version by default. Here are your options for on how to specify it;
- Handling it as an extension of the hostname part of the URI. As in; http://yourdomain.com/2.1/a-resource/1
- Handling with a custom version request header. As in; x-version: 2.1
- Handling in with part of the content-type. As in; Accept: application/vnd.awesome-type.v2.1. I don’t like this one as much since it is not obvious what is being versioned; content type or API itself.
Should you version your API to start with? I say it depends. My thinking is that if you are working with a single client such is the case for the backends for frontends approach, operational complexity it brings might not be worth it. But when you have a complex dependency matrix as is the case for micro-services most of the time, taking the time to tackle this problem starts to make more sense.
9. Organise Your API in a Simple and Consistent Way

Last but not the least. Don’t pick and choose the resources that you are going to provide these features. Support them in all of your resources so that people can have reasonable expectations about the way your API behaves. Figuring out just one of your resources should be enough to understand the whole thing. If you can do this, you may be pleasantly surprised that you are only going to need to update when your domain model changes, not every time that the needs of your consumers change.
Better yet, if you can provide all these features at the resource level, you can solve the age-old problem of orchestration vs choreography. While orchestration is neat and all, I’d say nothing is better than a powerful choreography if you have the feature-rich nodes to back it up. If you can get away with not having unique, ad-hoc services, don’t have them. It is not that hard when you spend time in your domain model so that everything has its place. Consistency and simplicity that comes with this are going to make everything easier to understand, maintain, and scale.
What about capability services? You may be thinking “not everything is a resource damn it!” but you’d be surprised that how much of the logic you need can be considered as a behaviour of an actor. But yes, sometimes what you need is just a function. Say, a service that sends an email or an SMS. When what you need is a pure function, that doesn’t keep any state, doesn’t create a persistent data that needs to be identified and accessed later, you should then go for a capability service. Otherwise, almost always opt for a resource.
So, GraphQL vs REST?
Let’s loop back to one of the first questions of the series now that we are about to wrap up. If you are familiar with the GraphQL, you might’ve noticed by then that it is just a good specification for the resource expansion concept with lots of branding. We are in the times every piece of tech that Facebook touches turns to gold, and I feel like lots of content creators riding the wave and hyping it up to senseless degrees without having a solid grasp on the things they talk about. Claiming GraphQL is the successor to REST is like claiming Facebook is the successor to the internet, while at best it is a sound implementation of the social networking aspect of it with good marketing.
This is it!
Thanks for coming along with me this far in this long series. It took way longer than I initially planned but I hope you benefited from it. This part also ended up a bit jammed up as each section could use an article of their own to do them justice. Please feel free to add something that I have missed that you think is important by responding; I’d really appreciate it. And don’t forget to say hi to us at contact@refineri.co.uk when you have the time. Cheers!