
Is REST still a valid approach to use when designing your service layer? It seems to be falling out of favour compared to its glory days when it was a buzzword in itself that can create some hype just by mentioning it like Big Data, Micro Services or CQRS. There are people claiming there are lots of limitations to RESTful services, and the approaches like GraphQL or Falcor are the real deal for a while now. But does it makes sense to treat those as successors to the REST as a style, or their scopes overlap in a meaningful way?
In reality, most of the problems and associated limitations of RESTful services comes from a lack of understanding what they really are. It is possible to see back-end layers claiming to be RESTful while being objectively worse in every way then even SOAP-based web services. This situation could be attributed to REST being a relatively vague style with an undefined set of guidelines rather than protocol or a specification in part. While this could be a trait quite powerful for someone that had the chance to work on enterprise level projects and gained some valuable experience to make their own decisions, it is a problem for developers that encountered fewer obstacles in their careers.
What I’ll try to do in this article, which will be a 2-parter, is to provide something more tangible to follow for developers, that can help them gauge their service layers maturity levels. I’ll try to go in depth as I can regarding its core values and best practices. Hopefully, by the end of it, you should be able to compare the scope of a feature-rich RESTful service layer with an implementation of something like GraphQL and decide by yourself whether it can be said that these are competing approaches or complementary at best.
I’m going to start by trying to define REST while providing part of its history to give some context and having a closer look at ideas that inspired it in section 1. In part 2, I will start to talk about REST’s core values that you should always stick to when in doubt, before finally giving a big set of guidelines that you can follow. Here we go.
What Is REST

The problem we’ve been trying to solve for a while, in its most basic description, is the machine to machine interaction. Distribution is a crucial part of every solution in life, and most of the time the system that provides the behaviour we need will reside elsewhere. So we almost always need an approach to handle communication between these machines.
In our case, we have been trying to find standardised ways to provide interfaces to our software for others to consume and vice versa. In ancient times we tried to solve this problem with RPC specifications such as SOAP, CORBA or JRMI but most of them suffered from issues regarding interoperability or poor implementations due to their complexity and verbosity.
At some point in time (2000 AD really), without much fanfare, a smart guy named Roy Fielding had the idea to take inspiration from a platform that successfully solved a much harder problem: machine to human interaction. World Wide Web was seemingly handling the complexity of its purpose with grace, and I think its fair to consider it as one of the greatest successes in the human history. If some guy had been charging a nickel anytime someone has visited a web page, it’s hard to deny that he’d be a very very rich person by now. So in its most simple definition, REST is an architectural style that approaches machine-to-machine interaction on the foundations that made Web an achievement. The Issues web solves while providing a good user experience were the very same ones; searching, combining, transforming data, caching, authentication, coupling, all in a distributed manner. So it was a good candidate to look for inspiration for machine-to-machine interaction as well, since developers themselves like good UX.
Popularisation of the style came at a later date when notably companies like Flickr started to use the technique to present their APIs to the world and frameworks like Ruby on Rails provided more accessible ways to create RESTful services. But a big part of the community got the wrong lessons from these developments. This new more hip way to develop services just meant sending JSON (or XML which was still a popular choice at that point) over HTTP for many. This resulted in a lot of poorly constructed back-ends all over that is hard to understand, consume and predict.
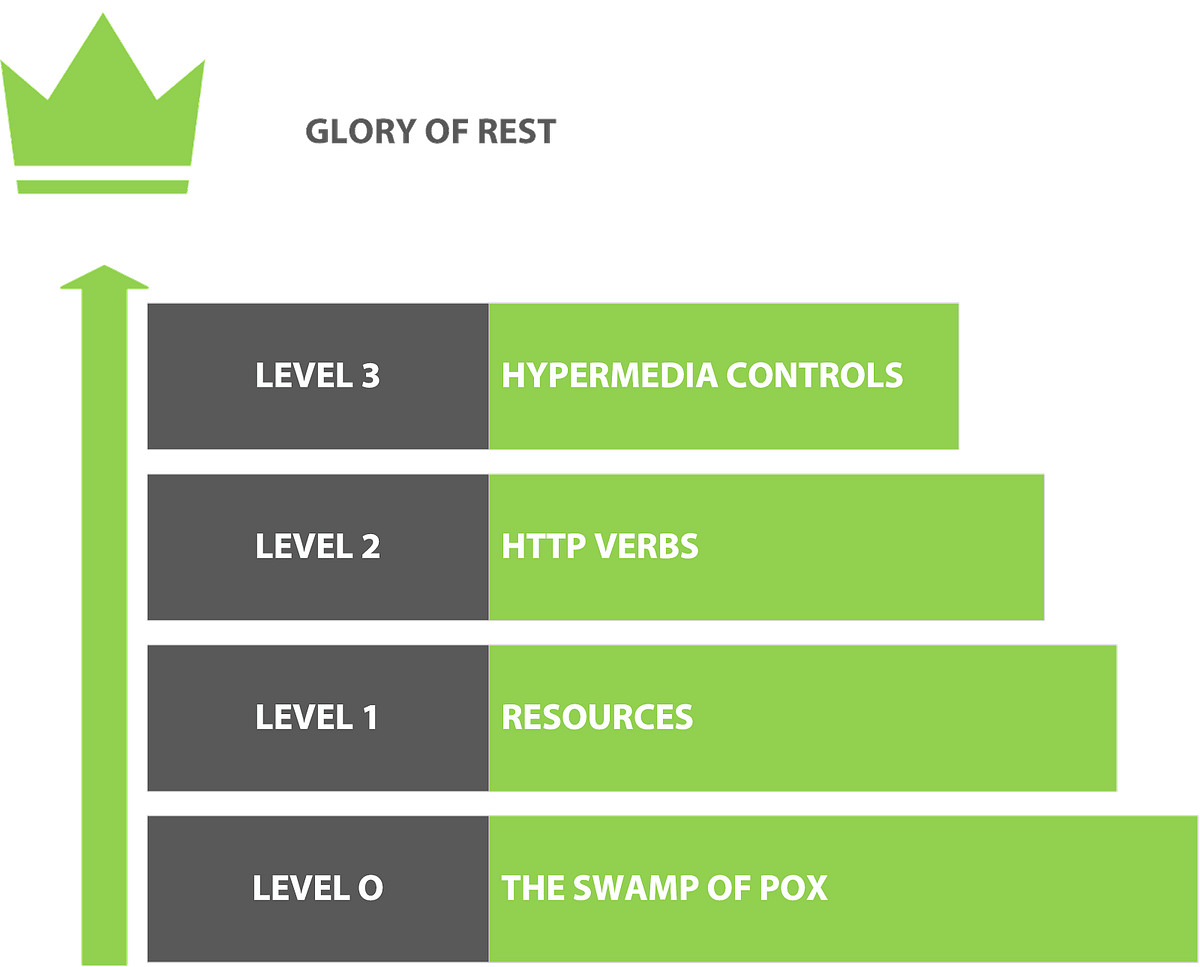
At some other point in time (2008 AD), another smart guy named Leonard Richardson came up with a straightforward scale that developers can follow to get close to the real glory of the rest; a maturity model to counter the unfortunate state of affairs related to REST. A few increasingly complex requirements that can help you figure out the distance between your services and Fielding’s original vision while giving you a few pointers about where to go next. It is a good starting point for anyone who is about to create a new API for their latest project and is still valid today. I will talk about it in detail what each step means later.
REST’s more proper definition might include expanding the acronym (It is “Representational State Transfer” by the way), but to make sense of it, I think we should go over the ideas that made web such a success.
Foundations of Web
So the first order of business is determining the foundations. What does web really does other than sending responses to you various requests without much protest?
It Thinks in Resources
Not much different than a company that has physical (or conceptual in some cases) resources, like boxes in a warehouse, web organises itself through resources. There are articles in news sites; there are images everywhere; there are products on e-commerce platforms. Each has its type helping their consumers about how to approach them. They are the basis of everything. Resources are named with nouns, not verbs by their very nature.
It Universally Identifies and Accesses Those Resources Through URIs
If you have a resource, you consequently need a way differentiate, access and manipulate it. Like pointers or handlers that help you access objects in memory, but universally in its network. That is what a URI (universal resource identifier) is for. It is something that you can share in an email, save as a bookmark or index in a database. The thing to look for here is, if a URI brings you different things each time, then it’s not a URI. When you share that fascinating piece of news with your friends through an email, if they don’t see the same thing with you then it’s not a URI.
Resources May Have One or More Representations
Resources may share their states through a representation in a known content type like HTML, PNG, JSON etc., in an attempt at encapsulation. While this is a requirement that is rarely abided by in web world, for a service to be stateless, these representations must be self-descriptive even though they may differ by the circumstances in which they are accessed.

It Allows NULL Pointers
As we all know by experience URI’s in web could be dangling. Web allows broken links to exist. While you may be annoyed when you see a 404 page politely reminding you that resource you are looking for no longer is there, it is definitely better than receiving an exception that crashes your flow. To quote “Rest in Practice” by Jim Webber, “Web, this modest status code set a new and radical direction for distributed computing: it explicitly acknowledged that we can’t be in control of the whole system all the time”.
Most of the time websites point you in the right direction of error recovery by giving you link that leads to the homepage to click on, so you can find what you’re looking for from there.
It Uses Hypermedia
Hypermedia was the big idea about Web. While we may take it for granted at this point, it is a brilliant approach that has very cute inspirations like the old choose your own adventure books. Tim Berners-Lee was the guy behind it when he designed the basic of the World Wide Web as a research fellow at CERN around 1990.
When you think about it, web unfolds like a state machine. Most of the time you know nothing but the initial state, like a home page. Then you see possible transitions from that page and choose your path accordingly. You keep going while discovering new possible ways to progress. This pattern is also visible in the use case of modification of the resources based on its state. Think of a web form that is acting a like wizard, where the user is guided through links and button to create and update a resource like new orders or newly registered users.
Hypermedia was literally the engine that drives the application state for the web. We’ll talk about this more in the second part when discussing HATEOAS.
It Is Powered By HTTP
Even though its name says “transport protocol”, its evident that HTTP is more than a transport protocol. We can see it’s not similar in purpose to TCP, UDP, etc. Its mechanics and tools like Status Codes, HTTP Methods, Content-Types and Headers are not needed if our only need was transferring data. All have great use in the flow of web and undoubtedly will have their places in RESTful web services as well.
What About Web Services?
In next part, I’ll continue with about how these foundations relate to web services and what are the core values we need to learn from those. It should be up in a week. I’ll update this article with a link when its uploaded so keep an eye on it.
Hello ,
I saw your tweets and thought I will check your website. Have to say it looks very good!
I’m also interested in this topic and have recently started my journey as young entrepreneur.
I’m also looking for the ways on how to promote my website. I have tried AdSense and Facebok Ads, however it is getting very expensive. Was thinking about starting using analytics. Do you recommend it?
Can you recommend something what works best for you?
Would appreciate, if you can have a quick look at my website and give me an advice what I should improve: http://janzac.com/
(Recently I have added a new page about FutureNet and the way how users can make money on this social networking portal.)
I wanted to subscribe to your newsletter, but I couldn’t find it. Do you have it?
Hope to hear from you soon.
P.S.
Maybe I will add link to your website on my website and you will add link to my website on your website? It will improve SEO of our websites, right? What do you think?
Regards
Jan Zac